Motivation
-
Unconsented Data Use: Modern music-generative models are frequently trained on vast amounts of web-scraped music without permission, stripping musicians of agency over their own creative works.
-
Beyond Training Risks: Even without training on protected songs, generative models can still exploit released tracks by extracting their style or using them as conditioning inputs for remixing, editing, or genre transfer.
-
Insufficient Existing Defenses: Prior defenses (e.g., HarmonyCloak) focus solely on degrading training performance and do not offer protection against feature extraction, conditioning, or post-training reuse.
-
Need for Artist-Centric Solutions: Independent musicians and smaller studios lack the resources for litigation or complex technical safeguards—necessitating a lightweight, perceptually safe, and practical defense tool.
-
Goal of MusicShield: To give musicians a way to proactively “shield” their music before release—disrupting unauthorized training, style imitation, and feature-based editing by generative models, while preserving artistic integrity.
Background
Recent advancements in music-generative AI systems pose a growing threat to professionals in the music production industry. These models learn from large datasets, often scraping publicly available music, and can edit, remix, and replicate an artist’s signature style without their consent. In this paper, we introduce MusicShield, a tool that enables musicians to apply “music shields” to their work before public release. These shields introduce subtle imperceptible perturbations to the audio signal, preventing generative models from learning or generating new music based on the artist’s work. While recent work (e.g., HARMONYCLOAK) focuses primarily on making music unlearnable to disrupt AI training, MusicShield not only prevents AI from training on music but also thwarts editing and manipulation, with improved scalability, lower computational cost, and better cross-model transferability. To evaluate MusicShield, we conducted user studies with 470 music professionals and enthusiasts to assess its effectiveness, usability, and perceptual tolerability, as well as their views on AI-driven music editing. Additionally, our quantitative evaluations across four state-of-the-art generative models (i.e., MusicLM, MusicGen, Jasco, and Riffusion) demonstrate its robustness and broad applicability. Our analysis shows that MusicShield withstands varied conditions and adaptive countermeasures while remaining lightweight and cost-efficient. User study results, together with quantitative metrics, confirm that MusicShield provides a practical and reliable solution for blocking unauthorized AI learning and editing in the generative AI era.
How MusicShield Works
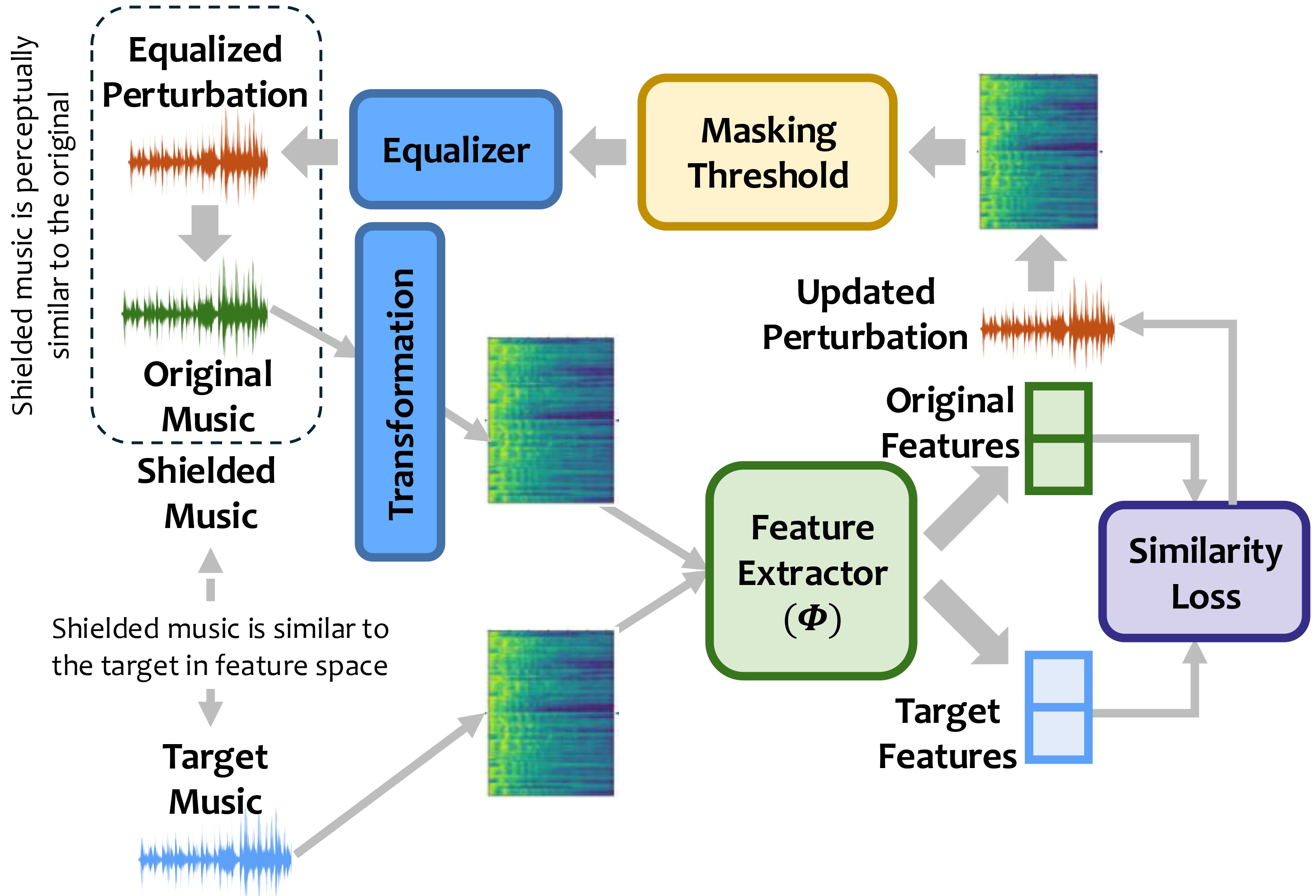
Target-Guided Feature Shifter
MusicShield modifies music at the waveform level by adding small perturbations designed to shift the perceptual and genre-related features of a track toward a selected target track. The target is chosen from a curated copyright-free library using perceptual and genre similarity scoring.
Psychoacoustic Masking
MusicShield uses a psychoacoustic masking model to ensure that perturbations added to the music remain imperceptible to human listeners. Specifically, we compute short-term frequency masking thresholds to identify time–frequency regions where added perturbations are masked by the original audio content.
Robust Perturbation Optimization
We use constrained optimization to generate perturbations that remain effective even after real-world audio transformations. This includes robustness to pitch-shifting, equalization, additive noise, and compression codecs like MP3, AAC, and OGG.
Perceptual and Semantic Loss Balancing
Our target selection combines perceptual similarity (OpenL3-based) and semantic divergence (genre classifier-based) between original and target music. This ensures that the shielded music still sounds like the original but confuses generative models during training, fine-tuning, or style transfer.
Music Samples
Perception Quality Assessment
| Samples | Original | Shielded |
|---|---|---|
|
Sample 1 |
|
|
|
Sample 2 |
|
|
|
Sample 3 |
|
|
Protection Against Music Editing
Generative models are capable of editing music by using the original track as a reference for generation. The editing process can be controlled by user prompts. MusicShield protects against unauthorized music editing by adding perturbations that steer the features of the original music toward those of a target track. By doing so, it redirects the generative model's output toward the target music instead of the original.
Original Music
Prompt: 8-bit Video Game Music (MusicGen)
Prompt: Hip-hop Music with Beats (Jasco)
Prompt: Rock Music with Drums & Guitars (MusicLM)
Prompt: Traditional Indian Music (Riffusion)
Shielded Music
Target Music
Prompt: 8-bit Video Game Music (MusicGen)
Prompt: Hip-hop Music with Beats (Jasco)
Prompt: Rock Music with Drums & Guitars (MusicLM)
Prompt: Traditional Indian Music (Riffusion)
Protection Against Unauthorized Model Training
MusicShield is also capable of preventing generative models from learning the features of the original music during training. Our approach introduces imperceptible perturbations that conceal the original music features, effectively steering the model to learn the characteristics of a predefined target track instead. We train each generative model using the FMA-small dataset (either original or shielded versions). Importantly, we use a single shared target track across all training samples, which provides a practical and efficient means to evaluate robustness at scale.